SWE 622, Spring 2017, Homework 3, due 3/22/2017 4:00pm.
Introduction
Throughout the semester, you will build a sizable distributed system: a distributed in-memory filesystem. The goal of this project is to give you significant hands-on experience with building distributed systems, along with a tangible project that you can describe to future employers to demonstrate your (now considerable) distributed software engineering experience. We’ll do this in pieces, with a new assignment every two weeks that builds on the prior. You’re going to create an actual filesystem – so when you run CFS, it will mount a new filesystem on your computer (as if you are inserting a new hard disk), except that the contents of that filesystem are defined dynamically, by CFS (rather than being stored on a hard disk).
While we’re not focusing on making this a high-throughput system (for simplicity, we are implementing the filesystem driver in Java, which will inherently add some sizable performance penalty compared to implementing it in native code), you should be able to see the application of our system on the real world: often times, we build services that need to share data. If the total amount of data that we need to store is large, then we’ll probably set up some service specifically devoted to storing that data (rather than storing it all on the same machines that are performing the computation). For performance, we’ll probably want to do some caching on our clients to ensure that we don’t have to keep fetching data from the storage layer. Once we think about this caching layer a little more, it becomes somewhat more tricky in terms of managing consistency, and that’s where a lot of the fun in this project will come in. Here’s a high-level overview of the system that we are building:
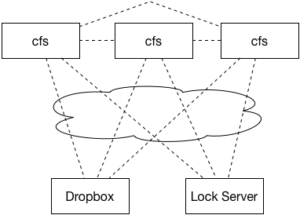
Each computer that is interested in using the filesystem will run its own copy of the filesystem driver (we’ll call it the CloudFS, or CFS for short). We’ll use Dropbox’s web API to provide the permanent storage, and will implement a cache of our Dropbox contents in our cfs driver. A lock service will make sure that only a single client writes to a file at a time (HW2). Over the course of the semester, we’ll set up the cache to be distributed among multiple CFS clients (HW3), distribute the lock server between the clients to increase fault tolerance (HW4), investigate fault recovery (HW5), and security and auditing (HW6).
Acknowledgements
Our CloudFS is largely inspired by the yfs lab series from MIT’s 6.824 course, developed by Robert Morris, Frans Kaashoek and the 6.824 staff.
Homework 3 Overview
We’re going to make a slight change to our system model of CFS for this assignment. In this assignment, we’re going to expand CFS so that we can improve the performance of the cache and make some first steps towards fault tolerance. This assignment, our architecture will look something like this:
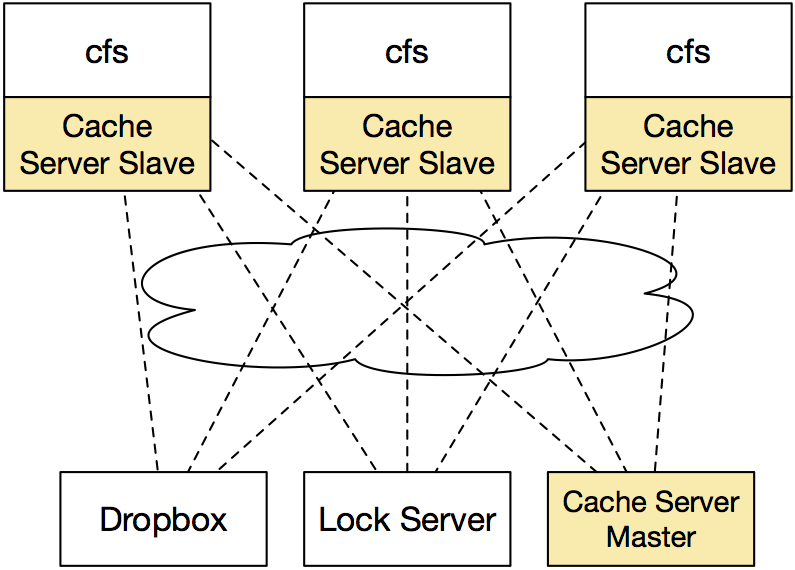
We’re going to start out by replicating our caching server. Thankfully, this task is made somewhat easier for us because we are building on top of Redis, which will do most of the heavy lifting. Recall that Redis supports master-slave replication out-of-the-box. In this model, a single Redis instance is the master, and any other instances are slaves. The master is in charge of performing all write operations and keeping the slaves up-to-date. In the event that a master fails, we could promote one of the slaves to become the master. In this assignment, we won’t yet consider failures, but instead will simply focus on getting CFS ready for that by introducing the replicas.
What we WILL get to benefit from is hopefully a decreased load on the main cache server. Now, the “master” server will be used ONLY for writes, and each CFS client will perform reads from its own “slave” Redis server. To start moving towards fault tolerance, we’ll also investigate building a simple heartbeat protocol, enabling the server to keep track of how many active clients there are at any given time.
There will be three tricky bits to this assignment:
- Implementing a simple “heartbeat” protocol between the client and the server so that the server can track how many clients are out there
- Maintaining ordering of writes between master + slave (using WAIT)
- Making sure all writes go to master, reads go to slave.
Your implementation of Homework 3 should build directly on your successful Homework 2 implementation. Hence, it is very important that you take the time to correct any issues from HW2 that prevent it from running. Please note that you have three weeks to complete this assignment, and hence, the expectation is that the basic filesystem operations (opendir, get, put, mkdir, mkfile, unlink, rmdir) all work as intended independently of any problems that might occur due to the replication being introduced in this assignment. Note: This assignment does NOT evaluate the correctness of the lock server (as implemented in HW2), and does NOT evaluate the correctness of how you use it. Hence, if you did NOT do that correctly for HW2, you should NOT worry about fixing it to avoid being penalized further, because you won’t. HOWEVER, this does not change the fact that basic filesystem operations should still work “correctly” for a single client (e.g. not crash, mkdir should still make a new directory in most cases, etc.). If you have any questions on this topic please ask me directly.
This assignment totals 80 points, and will correspond to 8% of your final grade for this course.
Getting Started
Start out by importing the HW3 GitHub repository. Then, clone your private repository on your machine, and import it to your ide. Copy your lock server from HW2 into your HW3 project. You may choose to start your HW3 CloudProvider from scratch, or build directly upon what you had in HW2 (in which case you should copy that code in to HW3 too). If you copy your RedisCacheProvider from HW2, please note that the constructor has changed for HW3 to pass not only the host and port for the redis master, but also for the intended slave.
You’ll notice there are now several projects in the repository:
-
fusedriver– Your CFS driver, just like in HW2 -
lock-shared– Shared RMI stubs used by the lock server and the CFS client, just like in HW2 -
lock-server– The Lock server code, just like in HW2
You’ll also find a Vagrantfile in the repository, similar to the configuration used for HW2, including Redis. The first time you start it, it will install the correct version of Redis. If it fails for any reason (for instance, network connectivity issues), try to run vagrant provision to have it re-try.
At a high level, your task is to modify your edu.gmu.swe622.cloud.RedisCacheProvider so that: (1) it runs the heartbeat protocol, (2) all writes go to the master Redis server and all reads go to the slave server and (3) all writes are protected with WAIT calls. The CloudFS class has been modified since HW2: now every time that you start CFS, it will launch a new Redis server on a random port, configure it to be a slave to the main Redis instance, and pass that port to your CloudProvider, so that you can use the slave for reading. When you stop the CFS client, that Redis server will be terminated. One cool lesson learned from this assignment should be that it’s incredibly easy to do replication with Redis (just look at the very tiny amount of code inserted on line 126 of CloudFS to create the replica), but that it’s not so trivial to do it with specific consistency guarantees.
Additional details are provided below.
Tips
You should copy your config.properties over from HW2.
You can run the lock server in the VM, by running:
|
1
2
|
vagrant@precise64:/vagrant$ mvn package
vagrant@precise64:/vagrant$ java -jar lock-server/target/CloudFS-lock-server-hw3-0.0.1-SNAPSHOT.jar
|
And, you can run the CFS client:
|
1 |
vagrant@precise64:/vagrant$ java -jar fusedriver/target/CloudFS-hw3-0.0.1-SNAPSHOT.jar -mnt cfsmnt
|
The first time you run it, you’ll need to re-authorize it for Dropbox (the config files that authorized it before were local to the HW1,2 VM).
If you want to remove what’s stored in Redis, the easiest way is using the FLUSHALL command in redis-cli:
|
1
2
3
4
|
vagrant@precise64:/vagrant$ redis-cli
redis 127.0.0.1:6379> FLUSHALL
OK
redis 127.0.0.1:6379> QUIT
|
Debugging remote JVMs
You can launch a Java process and have it wait for your Eclipse debugger to connect to it by adding this to the command line:
|
1 |
-Xdebug -Xrunjdwp:transport=dt_socket,server=y,address=5005
|
After you make this change, disconnect from the VM if you are connected, then do “vagrant reload” before “vagrant ssh” to apply your changes.
Then, in Eclipse, select Debug… Debug configurations, then “Remote Java Application”, then “create new debug configuration.” Select the appropriate project, then “Connection Type” => “Standard (socket attach)”, “Host” => “localhost” and “port” => 5005 (if you are NOT using Vagrant) or 5006 (if you ARE using Vagrant).
Testing
A good way to test this assignment will be to have multiple instances of CFS running, each mounting your filesystem to a different place. Then, you can observe if writes appear correctly across the clients. You can also independently test your heartbeat protocol by writing a stub that simply sends the heartbeat message and requests the number of active clients.
Part 1: Heartbeat (25 points)
Ultimately, our goal is going to be to make a best-effort attempt to make sure that every write gets to every replica. To do so, we’ll need to know how many replicas there are at any given point. One approach would be simply to have replicas message some server every time that they come online, and again when they disconnect. However, this wouldn’t account for the possibility of a replica failing at some point. One solution is to implement a “heartbeat” protocol, requiring the client to remind the server every so-often that it is alive. Then, the server can assume that if a client has not sent this heartbeat message recently that that client is offline.
We’ll use RMI to implement this protocol, combining the heartbeat server with the lock server (i.e., it will all be one RMI interface, and one RMI server). Our protocol is going to be fairly simple, containing the following methods:
|
1
2
3
4
|
public int register() throws RemoteException;
public void disconnect(int client) throws RemoteException;
public void heartbeat(int client) throws RemoteException;
public int getNumberOfActiveClients() throws RemoteException;
|
When a client comes online, it will call the register() method. The server will assign a unique ID to that client and return it back to the client. Then, every 30 seconds the client will call heartbeat(int) to the server, passing that unique ID that it was assigned upon calling register(). When a client intentionally wants to disconnect, it can call disconnect(int), passing its ID to the server.
Any client can call getNumberOfActiveClients at any time. This function will always return the number of clients that have sent the register() message or the heartbeat() message to the server in the past 33 seconds (note that this way the server allows a 3 second “grace period” to account for various latencies).
You are free to implement the server-side aspects of this however you like. One simple approach might be to keep a counter on the server to use to assign clientIds (perhaps an AtomicInteger), and then store a HashMap that maps from clientId to the timestamp of the most recent register or heartbeat message from that client. Disconnect would remove the clientId from that map. getNumberOfActiveClients would traverse the map and count the number of clients who have contacted in the past 33 seconds (let’s say that the server allows a 3 second grace period). You’ll be using this method in part 3.
For our purposes, you can assume that the network is well-behaved, and the only way a client might fail is by crashing. Hence, if you don’t receive a heartbeat message from a client, you can assume that it is now offline and will never return (or if it returns, it will come back as a brand new client having no recollection of its previous state). This approach will be imperfect: in the real-world, we would want to take into account network partitions, where a single heartbeat message is lost, and then the client reconnects later. What should we do in that scenario? The answer will probably depend on a lot of things, and require some tinkering on both the client and server side.
Hint: You’ll need to create a new thread on the client to send these regular heartbeat messages. Using a TimerTask might make sense.
Part 2: Redirecting Reads + Writes (25 points)
Modify your Redis filesystem cache in RedisCacheProvider. Note that the constructor for this class has changed: it now is passed two sets of port/hostnames to use for Redis – one will be the address and port of the master Redis instance, and one will be the address and port of a slave. We’ll want to redirect all WRITES to the cache to the master instance, and all READS from the cache (i.e. all queries that are NOT writes) to the slave. You’ll notice that in the provided base implementation of RedisCacheProvider, there are two JedisPools created – one for the master and one for the slave. This approach will (1) simulate a real-world environment where we utilized replication to reduce server load, and (2) demonstrate that the replication is working correctly. As in Homework 1 + 2, you are free to place your implementation across multiple methods/classes, but you may not modify CloudFS or CloudProvider in any way.
Part 3: Write consistency (30 points)
At this point, you should have clients reporting to the server when they are alive, writes being directed to the master, and reads directed to a slave. We need to do something special though to try to maintain consistency given Redis’ replication model. As discussed in Lecture 5, Redis does not make any guarantees about how quickly a slave will receive an update made to a master. HOWEVER, we can add some constraint here by using the WAIT command just after performing every write. As its name might suggest, WAIT will prevent the client who is doing writing from proceeding until the write message is propagated to each replica. Hence, if we call WAIT after making a write (and before releasing our write lock), we can be confident that once WAIT returns and we release our lock, any future process to try to read that value from a replica will be talking to a replica that has received the updated value.
How does WAIT know how many replicas there are that it should wait for? It doesn’t: you need to tell it. Conveniently, for this assignment there will be exactly as many Redis slaves as there are CFS clients: if there are 2 CFS clients running at once, then there will be 1 Redis master and 2 Redis slaves. Hence, you should use your getNumberOfActiveClients method just before calling WAIT to find out how many clients are currently active, and then WAIT for that many replicas to receive the write.
Submission
Perform all of your work in your homework-3 git repository. Write your answers for Part 3 in README.md. Commit and push your assignment. Once you are ready to submit, create a release, tagged “hw3.” Unless you want to submit a different version of your code, leave it at “master” to release the most recent code that you’ve pushed to GitHub. Make sure that your name is specified somewhere in the release notes. The time that you create your release will be the time used to judge that you have submitted by the deadline. This is NOT the time that you push your code.
Make sure that your released code includes all of your files and builds properly. You can do this by clicking to download the archive, and inspecting/trying to build it on your own machine/vm. There is no need to submit binaries/jar files (the target/ directory is purposely ignored from git). It is accepted (and normal) to NOT include the config.properties file in your release.
If you want to resubmit before the deadline: Simply create a new release, we will automatically use the last release you published. If you submitted before the deadline, then decide to make a new release within 24 hours of the deadline, we will automatically grade your late submission, and subtract 10%. Any releases created more than 24 hours past the deadline will be ignored.